В света на изкуствения интелект и машинното обучение, идеята за модел, който може безпроблемно да обработва гигантски обеми данни от интернет е Светия Граал. А най-новият пробив в тази област, който се доближава до тази заветна цел, е дело на един от водещите технологични гиганти.
LongNet е нов вариант на модела „Transformer“ или „Трансформатор„, представен от научен екип на Microsoft в тяхната статия „LongNet: Scaling Transformers to 1,000,000,000 Tokens„. Toй разполага с котекстов прозорец от 1 милиард токени! Но как този огромен капацитет на модела задава нови стандарти и променя играта в областта на изкуствения интелект и машинното обучение?
LongNet: Светият Граал в обработката на информация с мащабите на интернет
Токенът е основна единица на текст, която моделът обработва, като тя може да бъде дума, част от дума или пунктуация. В контекста на езиковите модели, по-голям брой токени означава, че моделът може да „помни“ и обработва по-дълги текстове наведнъж.
За сравнение, ChatGPT на OpenAI има контекстов прозорец от 4,096 токена, или около 3,000 думи, GPT-3.5-turbo има 8,000 токени, и най-големият модел GPT-4 има 32,000 токени.
Компанията Anthropic предлага модел, наречен Claude, който разполага с 100,000 токени.
LongNet превишава всички известни стандарти – с възможността си да обработва астрономичния брой от 1 милиард токени, равняващ се на 750,000,000 думи или 2,000,000 страници!
Това е 250,000 пъти повече токени от ChatGPT. Представете си разликата между прочитането на една глава от книга и преглеждането на цяла библиотека наведнъж.
В графиката, която виждате, използваме логаритмична скала, за да можем да покажем огромната разлика между милиардите токени на LongNet и хилядите токени на другите модели. Тази скала показва ясно колосалната разлика без да пренебрегва малките стойности.
Това не е просто стъпка напред – това е гигантски скок в технологията. С LongNet може би бихме могли да сканираме и анализираме цели части от интернет. Това би могло да промени начина, по който търсим информация, извършваме научни изследвания и анализираме големи данни.
Този пробив в технологията на трансформаторите отстранява ограниченията на сегашните големи езикови модели и има потенциал да промени коренно различни приложения, включително обработка на естествен език, компютърно зрение и други. Но какво всъщност е „Transformer“ и как работи?
Transformer: Как машината „прочита“ милиони книги и „разговаря“ с нас?
Трансформаторите са вид невронни мрежи, които се използват във върховите технологии за обработка на естествен език, като моделите GPT. Те бяха представени през 2017 година в статията „Вниманието е всичко, което ви трябва„, написана от учени от Google Brain.
Представете си трансформатора не просто като технологична система, а като усърден студент. Тази „машина-студент“ абсорбира информацията от милиони страници, стремейки се не само да я запамети, но и да я интерпретира, разбира и дори да създава нови текстове. Процесът е подобен на студент, който прелиства страници на книги в огромни библиотеки, усвоявайки нюансите на езика и особеностите на литературния израз.
Докато на пръв поглед изглежда, че тези модели „четат“ текст, в действителност те пресмятат и анализират текстовете чрез математика. Така разкриват взаимоотношенията между думите и интерпретират техните значени въз основа на контекста.
Въпреки това, крайно необходимо е да подчертаем, че методът на „обучение„, използван от трансформаторите, драстично се различава от човешкото учене. Трансформаторите разпознават образци и връзки в информацията, но не я „разбират“ по начина, по който го правим ние, хората.
Тази прецизна и детайлна обработка на информацията не би била възможна без „механизма на внимание„. Той помага на трансформаторите да се фокусират върху различни части от текста, като се приспособява към важните детайли и пропуска по-малко значимата информация. Така, вместо да обработва всеки елемент по еднакъв начин, системата ефективно разпознава и анализира ключовите моменти, което води до по-точно и пълноценно разбиране на съдържанието.
Затова, когато използвате модели като ChatGPT, имайте предвид, че сте в диалог с система, обогатена с гигантско количество информация, която е готова да я използва, за да комуникира с вас.
От класическия метод към модерен подход: LongNet астрономични брой токени
С въвеждането на LongNet от Microsoft, имаме нов механизъм наречен „разширено внимание“ (или „dilated attention“ на английски). Това е сякаш нашият „студент-машина“ разполага с нов метод на четене, където той придава особено значение на близки думи, докато едновременно с това е способен да преглежда бързо далечните части от текста без да губи контекста.
Тази новаторска техника позволява на модела“ да „чете“ още по-бързо, като същевременно не пропуска важни детайли. Представете си, че има способността да анализира няколко глави от книга едновременно, без да изпуска ключовите моменти.
А астрономичният брой от 1 милиард токени, който моделът може да обработва, само подчертава тази впечатляваща възможност.
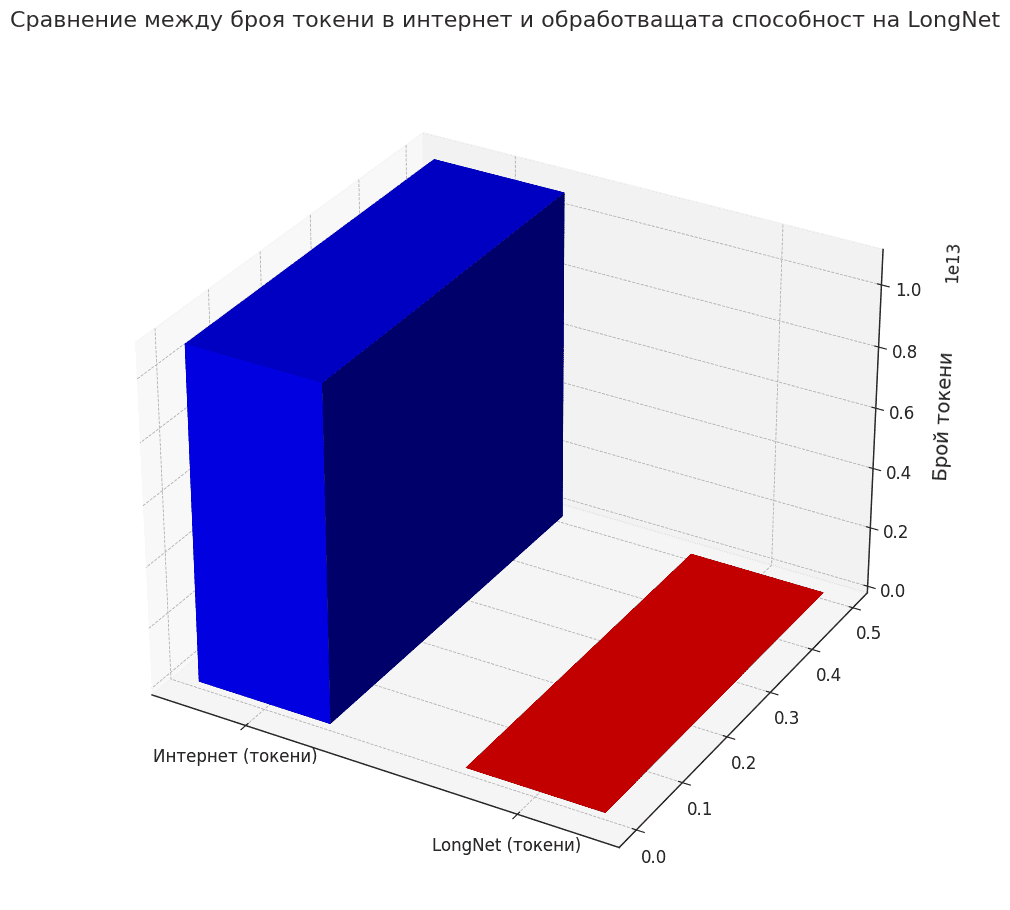
И за да дадем някакъв контекст на тази цифра – 1 милиард токена – представете си интернет. Световната мрежа се състои от над 1.13 милиарда уеб страници. Ако направим груба оценка и предположим, че всяка страница съдържа средно около 2,000 думи (което е по-скоро висока средна стойност, тъй като много страници съдържат много по-малко думи), и че всяка дума може да бъде считана за токен, то уебът би съдържал приблизително 2.26 трилиона токена.
Така че, докато LongNet все още не може да „прочете“ целия интернет за миг, възможността да обработва 1 милиард токени – което представлява около 0.044% от общия брой токени в интернет – е значителна стъпка напред към тази цел!
LongNet: Революцията в изкуствения интелект и новите перспективи пред Microsoft
Бъдещето на LongNet предвещава революция в технологиите. Очаква се моделът да може да обработва бази данни от несравними размери. Капацитетът му да абсорбира гигантски обеми информация обещава не само разширена памет, но и дълбок анализ на сложните причинно-следствени взаимоотношения.
Стратегическите планове на Microsoft включват разширяване на приложенията на LongNet в различни сфери, сред които мултимодални езикови модели, геномика и др.
Може би вече навлизаме в ново измерение на възможностите за генеративните AI модели, които потенциално могат да асимилират целия интернет наведнъж. Това е стъпка, която може да ни приближи до Общ изкуствен интелект или AGI (Artificial General Intelligence) и, в крайна сметка, до раждането на суперинтелигентност.
Целта на AIBulgaria.com е да предоставя актуална и стойностна информация от света на изкуствения интелект (AI). Последвайте ни в социалните мрежи – Facebook, Twitter и LinkedIn. Също така, може да се присъедините към нашия Discord сървър!