
Reka, стартъп за изкуствен интелект със седалище в Сан Франциско, основан от бивши изследователи на DeepMind, Google и Meta, представи нов мултимодален езиков модел, наречен Core.
Meet Reka Core, our best and most capable multimodal language model yet. 🔮
— Reka (@RekaAILabs) April 15, 2024
It’s been a busy few months training this model and we are glad to finally ship it! 💪
Core has a lot of capabilities, and one of them is understanding video – let’s see what Core thinks of the 3 body… pic.twitter.com/5ESvog35e9
Компанията твърди, че „Core е модел от най-висок клас, който осигурява водеща в индустрията производителност в широк спектър от задачи, включващи текст, изображения, видео и аудио“. Моделът е ефективно обучен от нулата с помощта на хиляди графични процесори (GPUs) за период от няколко месеца, посочват от компанията, като не разкриват точния брой параметри на модела. И Тай, главен учен и съосновател на Reka, написа в X (Twitter), че Core все още се „усъвършенства (обучението не е приключило), но екипът е впечатлен от представянето досега“.
Според сравнителните тестове, представени от компанията, Core е съпоставим с най-добрите модели на пазара, в това число GPT-4 на OpenAI, Claude от Anthropic и Gemini на Google.
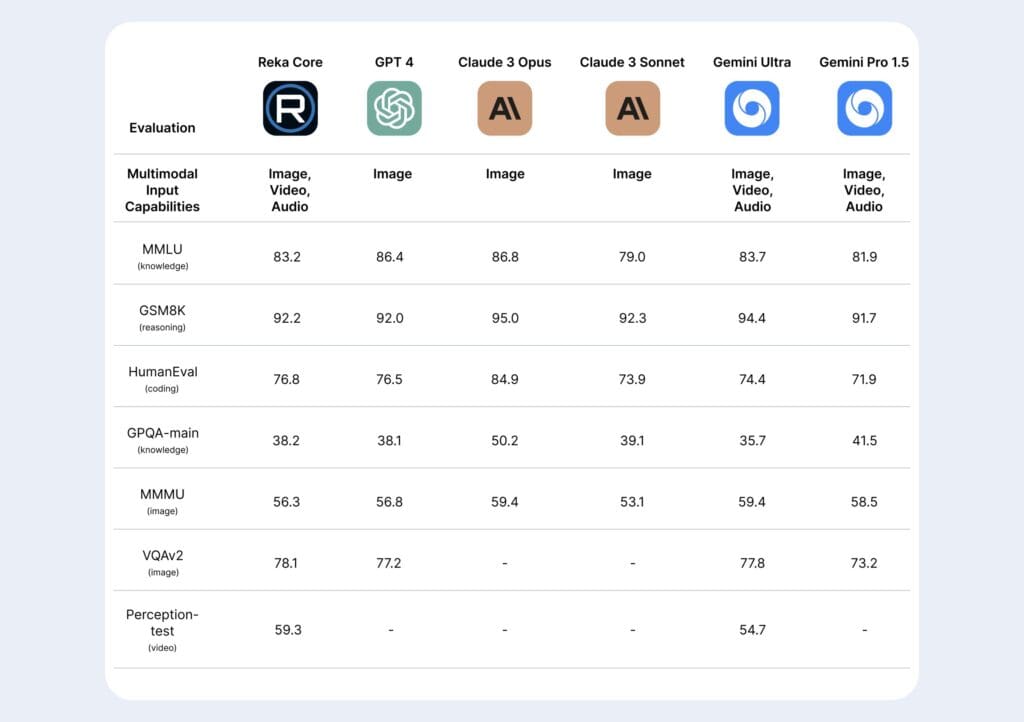
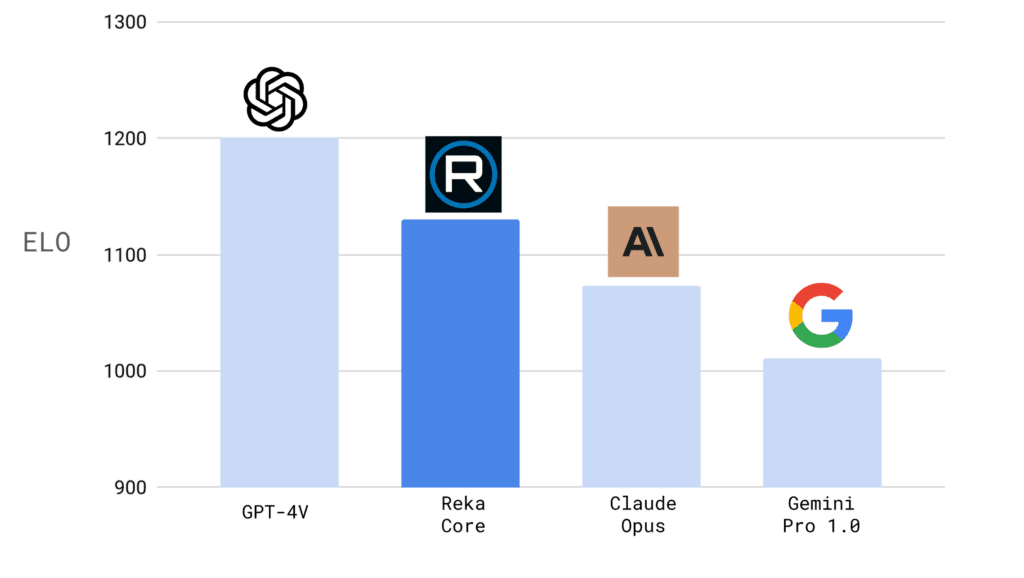
Едно от най-впечатляващите предимства на Core е неговото мултимодално разбиране на изображения и видео.
Това не е просто езиков модел от ново поколение – той притежава мощно контекстуализирано разбиране на изображения, видео и аудио
– споделят от компанията.

Core разполага и с голям контекстен прозорец от 128 хил. токена, което му позволява да приема и обработва голямо количество информация. Това, съчетано с превъзходните му способности за разсъждение, включително езикови и математически, според компанията го прави подходящ за сложни задачи, изискващи задълбочен анализ.
Моделът е наличен в чатбот приложението Poe, чрез API, а също така е достъпен и за клиентите на Snowflake и Oracle Cloud Infrastructure.
Последвайте ни в социалните мрежи – Facebook, Instagram, X и LinkedIn!